|
Como o padrão de codificação VC-1 proposto tem uma eficiência de compressão três vezes superior a do MPEG-2 e entrega conteúdo HD em taxas de bits tão baixas como 6 Mbits/s e 8 Mbits/s, os broadcasters podem dispor de mais banda para expandir a programação e serviços para seu público. Os usuários domésticos serão capazes de armazenar mais conteúdo nos seus gravadores de vídeo pessoais. Um filme de longa metragem, em alta definição, poderá ser armazenado em um DVD com seu padrão de qualidade intacto. O mesmo conteúdo HD poderá ser reproduzido nos atuais PCs domésticos, usando apenas decodificação por softwares. Pelo lado da produção, muitos produtores independentes oferecem suporte para essa tecnologia de codificação, incluindo soluções de codificação HD em tempo real para sua produção diária digital ou entrega final.
Este artigo cobre as características inovadoras do VC-1, incluindo o uso de transformada adaptativa de blocos com altas taxas de compressão, enquanto preserva detalhes de baixo nível, tais como granulação de filme, aritmética de 16-bits para melhorar a eficiência computacional e outras ferramentas que otimizam o conteúdo para uma variedade de aplicações, incluindo rede de TV aberta, reprodução de cenários e produção de DVD. Este artigo também descreverá detalhes do plano de configuração incluindo o decodificador de referência para VC-1, recentemente lançado, assim como o novo companheiro de trabalho para o MPEG-2, para fins de transporte.
Panorama do VC-1
O panorama a seguir é baseado no Comitê de Trabalho C-24, em andamento, e está sujeito a mudanças dependendo da conclusão do grupo. Foi revisto e aprovado para publicação, pela SMPTE com esta premissa.
Descrição Geral
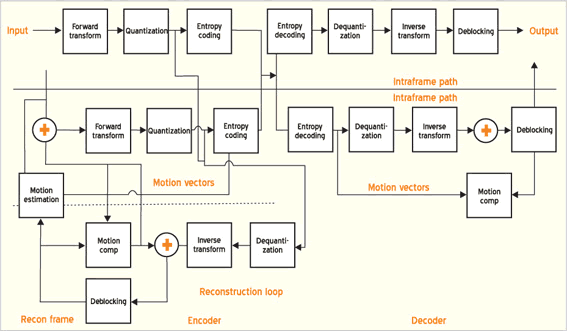
O VC-1 é um codificador de vídeo que faz transformação e compensação de movimento de blocos, usando quadros I, P e B e uma estrutura de amostragem de 8 bits, 4:2:0. O codec usa compensação de movimento baseada em blocos e esquema de transformação espacial que, em alto nível, é similar a todos os padrões populares de compressão de vídeo, desde o MPEG-1 até o H.261.
O diagrama de blocos, em alto nível, do codec é mostrado na fig. 1. Faz-se uma previsão do bloco atual procurando um bloco anterior de mesmo tamanho, reconstruído, e que foi deslocado da sua posição pelo vetor de movimento. Subseqüentemente, a diferença entre os dois quadros, ou erro residual, é computada como o desvio entre o bloco atual e sua previsão feita pela compensação do movimento. Esse erro residual é formatado em outro espaço usando uma transformada linear de compactação de energia; depois é quantizado e codificado por entropia.
|
|
Pelo lado do decodificador, os coeficientes quantizados são decodificados por entropia, desquantizados e sofrem a transformada inversa, para produzir uma aproximação do erro residual, que é então adicionada a previsão de movimento compensado para gerar a reconstrução.
O restante desta seção descreve os principais procedimentos do VC-1, incluindo inovações que o distinguem de outras soluções de codificação de vídeo, tais como os padrões MPEG. (Ver a proposição SMPTE 421M1 para mais detalhes sobre o VC-1)
Codificando Quadros
O VC-1 usa quadros: intra (I), prévios (P) e bidirecionais (B). Os quadros I são aqueles codificados de forma independente e que não dependem dos outros quadros. Os quadros prévios são aqueles que dependem de um quadro anterior. Os quadros bidirecionais são aqueles que têm duas referências temporais – uma do quadro anterior e outra do posterior. Essas definições de quadros I, P e B se aplicam para ambas as varreduras: progressiva e entrelaçada.
Transformada do tamanho adaptado do bloco
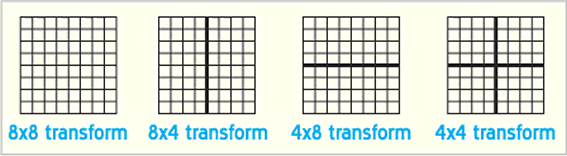
Tradicionalmente, as transformadas 8×8 são usadas para codificação de imagem e de vídeo. O tamanho 8×8 é amplo o suficiente para captar tendências e periodicidade. Entretanto, transformadas menores ficam melhores em áreas com descontinuidades porque elas produzem menos ringing 2,3 . O VC-1 permite as seguintes opções para um bloco 8×8: um único bloco 8×8, dois blocos 8×4 unidos horizontalmente, dois blocos 4×8 unidos verticalmente, ou quatro blocos 4×4, como mostra a fig. 2.
Isso permite ao VC-1 usar tamanho e forma mais adequados da transformada para o detalhamento dos dados. Essa configuração específica da transformada é sinalizada como parte do bit stream no quadro, no macrobloco e no bloco. Se o sinal é enviado no nível do quadro, todos os blocos, dentro do quadro, usam o mesmo tipo de transformada. Do mesmo modo, se o sinal for enviado no nível de macrobloco, todos os blocos dentro dele (há seis blocos 8×8 em todos, quatro de luminância e dois de crominância) usam o mesmo tipo de transformada. A sinalização para o nível de bloco é especificada para o bloco atual. O macrobloco e a sinalização de nível de bloco podem ser misturados através dos macroblocos, dentro de um quadro. Isso permite uma boa variação na especificação do tipo da transformada, que é útil quando os dados são não-estacionários. A sinalização ao nível de quadro ajuda em situações de taxa baixa, onde a folga usada no tipo de transformada da codificação pode ser maior, se esse tipo é enviado para o nível de macrobloco ou bloco.
Quando se usa sinalização ao nível de bloco ou macrobloco, há a possibilidade de salvar alguns poucos bits em áreas estática ou perfeitamente previstas. Quando, para o tipo de transformada escolhida, todos seus coeficientes quantizados em um bloco ou macrobloco são zeros, não há necessidade de enviar a informação do tipo de transformada, pois todas as variações da transformada inversa irão produzir blocos nulos para todas as entradas zeradas.
Isto permite que a folga seja reduzida para áreas estáticas ou para aquelas que podem ser geradas puramente por compensação de movimento. Este é o fator determinante para melhorar o desempenho em taxas baixas ou para seqüências de poucos movimentos como as cabeças de pessoas que estão conversando. Os quadros I e os intra blocos, nos quadros previstos, usam transformadas 8X8.
Aritmética de 16 bits
Os quatros tamanhos de transformadas usadas para adaptação dos blocos tornam a tarefa de projetar a transformada VC-1 um desafio. Uma importante motivação para o projeto da transformada é minimizar a complexidade computacional do decoder . Uma transformada inversa que pode ser implementada em aritmética de ponto fixo com 16 bits, reduz significativamente a complexidade computacional do decoder , quando comparada a uma de ponto flutuante para 32 bits, ou 8X8, ou 8X4, ou 4X4 ou 4×4. Primeiro, as operações de 32 bits são caras para serem implementadas em processadores de 16 bits, que representam um alto percentual dos Processadores de Sinais Digitais (DSPs – Digital Signal Processors) usados atualmente.
Segundo, se o resultado da multiplicação de dois números de 16 bits pode estar restrito em um registro de 16 bits, é possível obter um acréscimo de velocidade computando duas operações de 16 bits, simultaneamente, em um registro de 32 bits em paralelo, com uma programação inteligente quando a aritmética de 32 bits está disponível.
Finalmente, o dobro do número de operações de 16 bits pode ser feito em um ciclo de 32 bits para operações de SIMD (Single Instruction-Stream, Multiple Data-Stream) tais como aquelas definidas por MMX (Matrix Math Extensions) no Pentium.
As transformadas VC-1 são projetadas para atender a lista de restrições apresentada a seguir. As transformadas são separáveis, o que permite que as restrições sejam definidas para cada dimensão do estágio da transformação. As restrições para ambas as transformadas, de uma dimensão, com 4 e 8 pontos são:
Os coeficientes das transformadas são inteiros pequenos. A transformada é uma operação de 16 bits, onde ambos, a soma e o produto de dois valores de 16 bits produzem resultados em 16 bits.
As transformadas, direta e inversa, formam um par ortogonal. Isto é definido da seguinte forma: Sejam U e V as transformadas diretas e inversas, então U e V são biortogonais se VU = diag (D). Além disso, V e U são ortogonais quando V=U’ (U’ é a matriz inversa de U). Não é necessário que o produto seja uma matriz identidade; qualquer matriz diagonal é um produto válido para a ortogonalidade e bi-ortogonalidade – qualquer fator de escala introduzido por elementos diferentes de 1 na diagonal não unitária do produto, pode ser introduzido durante a quantização.
A transformada se aproxima de uma transformada Discreta de Coseno (DCT), que é conhecida por ter propriedades favoráveis de compactação da energia em dados de vídeo intra ou residual.
|
|
As normas das funções básicas, dentro de um tipo de transformada, são idênticas, portanto isso elimina a necessidade de re-normalização de qualquer coeficiente indexado no processo de desquantização.
As normas das funções básicas entre tipos de transformadas são idênticas. Em outras palavras, as funções básicas de 4 e 8 pontos têm a mesma norma. Isso permite o uso do mesmo parâmetro de quantização entre os vários tipos de transformadas, maximizando o desempenho da taxa de distorção.
A transformada inversa VC-1 é constituída das seguintes transformadas: uma 8X8, uma 4X8, uma 8×4 e uma 4X4. A faixa de expansão associada com qualquer ponto N da transformada do tipo DCT é maior do que uma associada a um ponto M da transformada quando N>M. Entre todas essas transformadas, a inversa 8X8 ocupa a restrição mais apertada na faixa daquelas com coeficientes inteiros, e é impossível encontrar uma 8×8 que satisfaça a todas essas restrições simultaneamente. A grande inovação no VC-1 é suavizar as restrições 5 e 6, permitindo que as bases dos coeficientes das transformadas estejam muito próximos, mas não idênticos, pela norma. Essas pequenas discrepâncias entre as normas das funções básicas são contempladas inteiramente no lado do codificador, sem perda da eficiência na compressão.
Compensação do movimento
A compensação do movimento gera uma previsão de um quadro de vídeo pelo deslocamento do quadro de referência. O deslocamento é definido pelo vetor de movimento (MV). Os componentes do MV são especificados em termos de deslocamentos do pixel freqüentemente com a precisão de sub-pixel. Os interpoladores são usados para filtrar o quadro de referência e daí gerar deslocamentos de sub-pixels.
A eficiência de um codec de vídeo está relacionada à capacidade do compensador de movimento gerar um bom conjunto de preditores. Enquanto uma alta resolução para o MV e blocos menores podem melhorar a eficiência da compensação de movimento, eles também aumentam a folga de sinalização para o MV e a complexidade computacional 4,5. O uso de filtros maiores para interpolação de sub-pixels, também pode melhorar a previsão, mas aumentam a complexidade. As soluções de compromisso do VC-1 para essas considerações passam por três critérios: resolução do MV, tamanho da área predita e tipo de filtro. O modo combinado do MV é um dos abaixo:
Tamanho de bloco misto (16 X16 e 8X8), ¼ pixel, bi-cúbico.
16X16, ¼ pixel , bi-cúbico.
16X16, ½ pixel , bi-cúbico.
16X16, ½, pixel, bi-linear.
O modo combinado do MV é sinalizado ao nível do quadro. Em geral, taxas maiores de bits tendem a usar os modos do topo da lista e vice-versa. A consolidação desses três critérios em um nos leva à implementação de um decoder mais compacto, sem perda significativa no desempenho.
Quantização e desquantização
A quantização e desquantização dos coeficientes da transformada são passos críticos que podem afetar o grau de distorção, ou desempenho do codec de vídeo. O VC-1 usa a quantização escalar, onde cada coeficiente da transformada é quantizado e codificado independentemente. Em alto nível, esse processo é similar ao seu correspondente nos padrões MPEG.
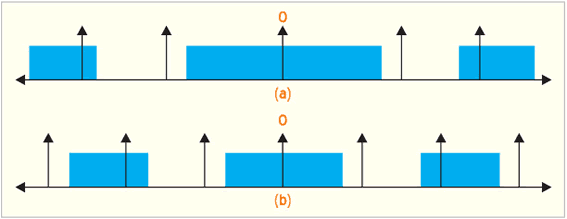
O VC-1 permite ambos, zona morta (não uniforme) e a quantização regular uniforme, isto é, ambas as variações, mostradas na fig. 3, são possíveis. O tipo especificado de quantização é sinalizado em nível de quadro e a regra de desquantização apropriada é aplicada para todos os coeficientes dentro do quadro pelo decodificador. O uso de uma zona morta gera substancial economia de bits, em baixas taxas, enquanto a quantização uniforme é freqüentemente mais apropriada para taxas de bits mais altas.
A opção de comutação entre as quantizações tipo zona morta e regular é, em taxas altas ou baixas de bits, um diferencial no desempenho do VC-1.
Filtragem em loop
O erro de quantização em blocos intra-codificados e nos resíduos dos blocos com movimento compensado (inter-codificados) pode induzir descontinuidades nos contornos dos blocos. Essas descontinuidades apresentam-se como artefatos (blocky)(2), visíveis nos quadros de vídeo reconstruídos. Além do mais, a qualidade do quadro reconstruído, como uma previsão para futuros quadros, é reduzida. O esquema VC-1 usa um filtro em loop(realimentado) para alisar essas descontinuidades, nos contornos dos blocos. A filtragem é realizada no quadro reconstruído antes dele ser usado como referência para o quadro posterior. O processo de filtragem opera nos pixels da bordas dos blocos vizinhos. Para imagens P e B, as fronteiras dos blocos podem ocorrer a cada 4ª, 8ª, 12ª e assim por diante, linha ou coluna do pixel dependendo se é usada uma transformada 8X8, 8×4, 4×8 ou 4×4. Para figuras I, a filtragem ocorre a cada 8ª, 16ª, 24ª, e assim por diante, linha ou coluna, de pixel já que somente são usadas transformadas 8×8.
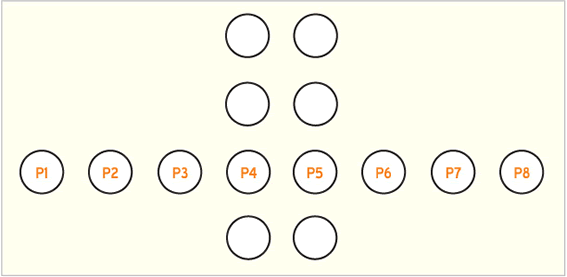
A figura 4 mostra os pixels que são envolvidos numa operação de filtragem. Nesse caso, uma fronteira vertical está sendo filtrada. As colunas contendo P4 e P5 representam as fronteiras entre dois blocos adjacentes transformados. Conforme ilustrado na fig. 4, oito pixels estão envolvidos na computação da filtragem, quatro para cada lado da fronteira do bloco.
|